Grandream
Amazon ECSのオートスケーリングが最大3.5倍高速化!20秒メトリクスの衝撃と実務への応用

アップデートの概要:スケーリングの遅さがついに解消
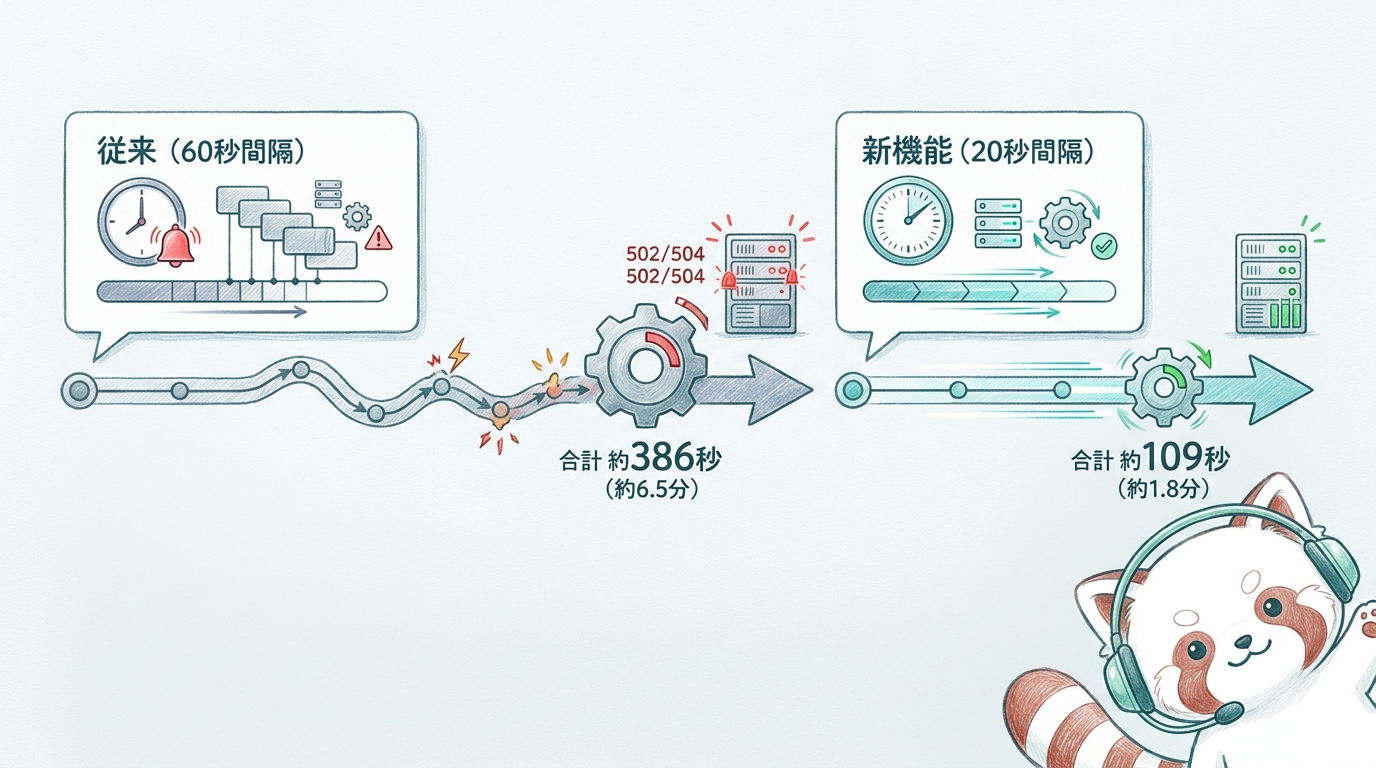
AWSから2026年6月18日、Amazon ECSのサービスオートスケーリングに関する非常に魅力的なアップデートが発表されました。結論からお伝えすると、ターゲットトラッキングポリシーにおいて高解像度(20秒間隔)のメトリクスが利用できるようになり、スケールアウトにかかる時間が最大で3.5倍(386秒から109秒へ)高速化されます。
これまで、突発的なスパイクアクセスに対して「ECSのスケーリングが間に合わず、処理遅延やエラーが発生してしまう」という悩みを抱えていたSREやインフラエンジニアの方にとって、今回の機能強化は長年の課題を解決するブレイクスルーとなります。さらに、スケールアウトが速くなることで、平常時に確保しておくべきタスクのベースライン容量を削減でき、結果としてコンピューティングコストの最適化にもつながります。
本記事では、このアップデートの仕組みや、実際のプロジェクトにどのようなインパクトをもたらすのか、そして具体的な設定手順や運用上の注意点について、実務家の視点で徹底的に解説します。
従来の課題と「20秒メトリクス」による高速化の仕組み
60秒メトリクスの制約と「遅い」原因
従来のECSサービスオートスケーリング(ターゲットトラッキング)では、デフォルトのメトリクス取得間隔が「60秒」に設定されていました。そのため、トラフィックが急増してCPUやメモリの使用率が跳ね上がったとしても、CloudWatchがその状態を検知してアラーム状態に遷移し、スケールアウトのアクションをトリガーするまでに大きなタイムラグが存在していました。
具体的には、メトリクスの評価に数分、そこから新しいタスクのプロビジョニングとロードバランサー(ALBやNLB)への登録作業を含めると、合計で5〜6分程度を要するのが一般的でした。短時間でアクセスが急増するシステムにおいては、この「5〜6分の空白期間」が致命的なボトルネックとなっていたのです。
20秒メトリクスへの対応と劇的なベンチマーク結果
今回のアップデートにより、CPUおよびメモリ使用率のターゲットトラッキングポリシーにおいて、従来の60秒に加えて「20秒」の高解像度メトリクス(High Resolution Metrics)がサポートされました。
AWS公式のベンチマークテストによると、この20秒メトリクスとメトリクス発行の最適化を組み合わせることで、以下のような劇的な改善が確認されています。
- スケールアウトのトリガー時間: 363秒から86秒に短縮(76%高速化、4.2倍)
- スケールアウトと新規タスクプロビジョニングの合計時間: 386秒から109秒に短縮(72%高速化、3.5倍)
これまで5分以上かかっていたタスクの追加が、わずか2分弱(109秒)で完了するようになったことは、ECSの運用において非常に大きな進化です。
実務への応用メリット1:スパイク耐性の劇的な向上
突発的なアクセス増加に対する迅速な追従
例えば、テレビ放映やプッシュ通知を契機とするキャンペーンサイト、フラッシュセールを実施するECサイト、チケットの発売開始時など、トラフィックが秒単位で急激に立ち上がるシステムでは、迅速なスケールアウトが必須要件となります。109秒で新しいタスクがプロビジョニングされ、トラフィックを処理し始められるようになれば、システムは負荷の急増に対してはるかに俊敏に反応できるようになります。
502/504エラーの回避とユーザー体験の向上
スケーリングが間に合わない状態が続くと、既存のコンテナ(タスク)がリソース不足に陥り、レスポンスの遅延や「502 Bad Gateway」「504 Gateway Timeout」といったエラーがユーザーに返されてしまいます。スケールアウト速度が3.5倍になることで、タスクの枯渇期間が大幅に短縮され、ユーザー体験の低下や機会損失といったビジネス上のリスクを未然に防ぐことが可能になります。
実務への応用メリット2:ベースライン最適化によるコスト削減
過剰なプロビジョニング済みタスクの削減
従来、ECSの「遅い」スケーリングをカバーするためには、スパイクに備えて常にベースライン(最小)のタスク数を多めに確保しておく「オーバープロビジョニング」という手法がとられがちでした。例えば、本来であれば平常時はタスク2台で十分なシステムでも、スパイク発生後5分間の耐久性を確保するために、あらかじめタスクを10台並べておくといった運用です。
コンピューティングリソース全体の最適化
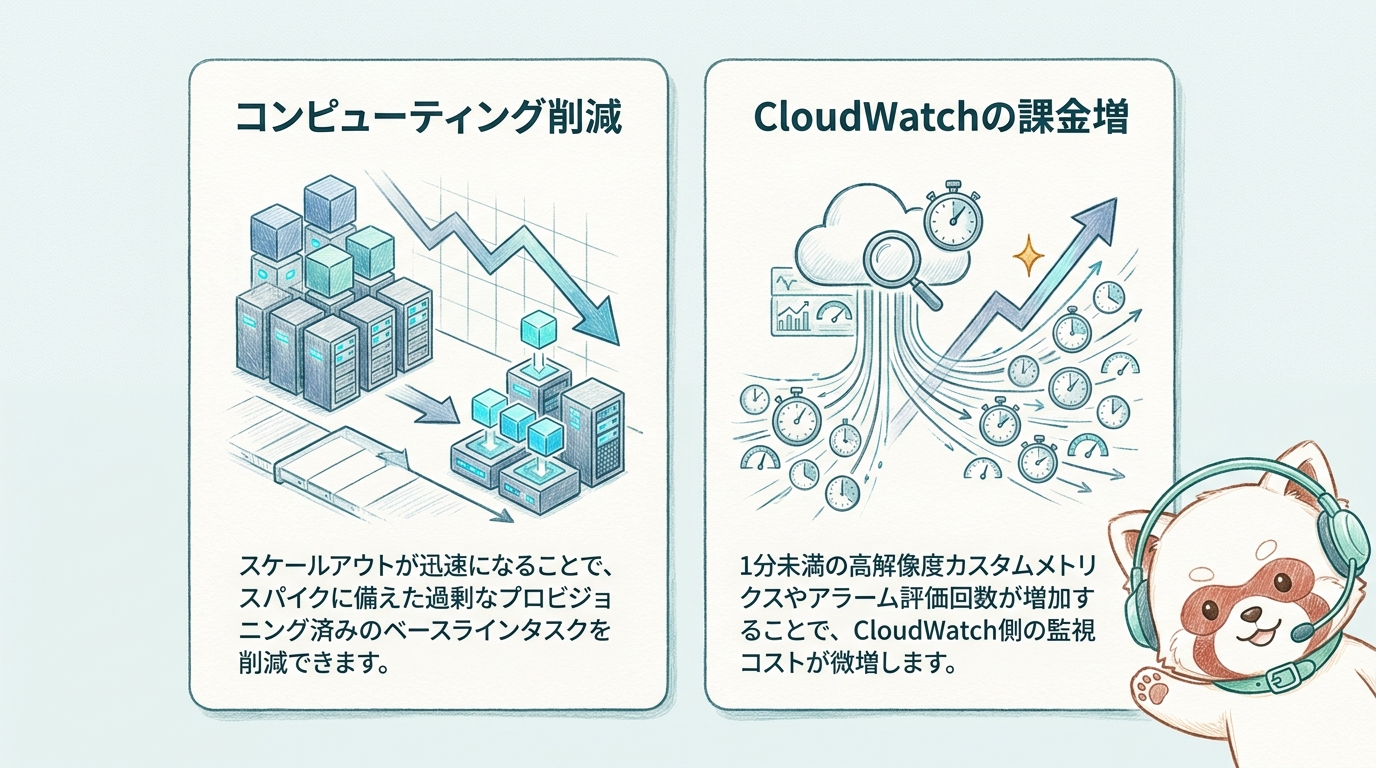
スケールアウトが迅速に行われるようになれば、こうした「保険」としての過剰なタスク待機を減らすことができます。ベースライン容量をギリギリまで引き下げ、トラフィックの変動に合わせて動的にタスクを増減させられるため、AWS FargateやAmazon EC2のコンピューティングコストを大幅に抑えることができます。スケーリングの俊敏性は、直接的にコスト効率の向上をもたらします。
高解像度メトリクスの設定手順
今回の機能は、AWS Fargate、Amazon ECS Managed Instances、Amazon EC2のすべてのECSコンピューティングオプションで利用可能であり、設定も非常にシンプルです。
AWSマネジメントコンソールからの設定
マネジメントコンソールを使用する場合は、ECSサービスの「更新」画面(または新規作成画面)から以下の手順で設定します。
- 「サービスオートスケーリング」のセクションを開きます。
- ターゲットトラッキングポリシー(CPU使用率、またはメモリ使用率)を追加・編集します。
- ターゲットトラッキングの設定項目内に、新しく追加された**「20秒」のメトリクス解像度**を選択するプルダウンがあるため、これを指定して保存します。
CLIおよびIaC(CloudFormation等)での対応
AWS CLI、AWS CloudFormation、TerraformといったIaCツールでも対応可能です。対象となるスケーリングポリシーのプロパティにおいて、高解像度の定義済みメトリクスを指定するようにテンプレートを更新します。
例えば、AWS CLIやCloudFormationでターゲットトラッキングのポリシーを定義する際、高解像度メトリクス(20秒間隔での評価)を指定するパラメータを追記することで有効化できます(詳細なプロパティ名は最新のAWS公式ドキュメントをご参照ください)。
注意点とトレードオフ:CloudWatchの課金増
高解像度カスタムメトリクスの料金体系への影響
この強力な機能を導入する上で、実務上必ず押さえておくべきなのがAmazon CloudWatchの料金に関するトレードオフです。
1分未満の頻度でデータポイントを送信・評価する「高解像度メトリクス(High Resolution Metrics)」は、標準のメトリクス(60秒間隔)とは異なり、追加の課金対象となります。具体的には、高解像度のカスタムメトリクスやアラームの評価回数が増加することで、CloudWatch側のランニングコストが上昇します。
導入にあたってのコストシミュレーションの推奨
ベースラインタスクの削減によって得られる「ECS(Fargate/EC2)コンピューティングコストの削減額」と、20秒メトリクスの利用に伴う「CloudWatchの追加料金」を比較検討することが重要です。 トラフィックの変動が激しいサービスではコンピューティングコストの削減メリットが大きく上回るケースが多いですが、トラフィックが一定でタスク数が少ないサービスにおいては、逆にコスト増となってしまう可能性もあります。本番環境に適用する前に、まずは対象サービスの特性を見極め、コストシミュレーションを実施することを強くお勧めします。
まとめ:まずは開発環境で検証を
今回のAmazon ECSオートスケーリングの高速化(386秒から109秒への短縮)は、長年現場で運用を担ってきたエンジニアにとって待ち望んだ強力なアップデートです。20秒の高解像度メトリクスを活用することで、迅速なスケールアウト要件に高いレベルで応えつつ、不要なコンピューティングリソースの削減によるコスト最適化を実現できます。
「トラフィック急増への不安」と「過剰なプロビジョニングによる無駄なコスト」を同時に解消できる可能性があるため、まずは開発・検証環境のECSサービスで20秒メトリクスを有効化してみてください。負荷テストツールを用いてトラフィックをかけ、実際のスケールアウト完了までのタイムラインやシステムの挙動を確認することで、自社プロダクトへの導入判断がスムーズに行えるはずです。
参考文献
Amazon ECS、より高速なサービスオートスケーリングを発表 https://aws.amazon.com/about-aws/whats-new/2026/06/amazon-ecs-faster-autoscaling/

Grandream
株式会社グランドリーム
AI・システム開発のプロフェッショナルチームです。AIエージェント・業務自動化・Webシステム開発などを手がけています。